- 博客/
Rancher 单机部署,进行升级后,导致docker无法正常启动
作者
Johny
熟练的 云原生搬砖师
Table of Contents
环境说明#
- 操作系统: Centos 7.9.2009
- Docker Version: 18.09.9
模拟复现#
rancher 安装#
docker pull rancher/rancher:v2.3.5
docker run -d \
--restart=unless-stopped \
--name rancher \
-p 80:80 -p 443:443 \
--privileged \
rancher/rancher:v2.3.5
升级 rancher#
示例将
v2.3.5升级至v2.5.0
创建备份#
docker stop rancher
docker create --volumes-from rancher --name rancher-data rancher/rancher:v2.5.0
docker run --volumes-from rancher-data -v $PWD:/backup busybox tar zcvf /backup/rancher-data-backup-rancher2.3.5-20210116.tar.gz /var/lib/rancher
重新启动新容器#
docker rename rancher rancher_old
docker run -d --name rancher --volumes-from rancher-data \
--restart=unless-stopped \
-p 80:80 -p 443:443 \
--privileged \
rancher/rancher:v2.5.0
docker logs -f --tail 100 rancher
docker update --restart=no rancher_old
问题表现#
系统重启 或 手动重启 docker 服务时,docker 卡死无法启动

/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock # 手动启动,报错
Error starting daemon: pid file found, ensure docker is not running or delete /var/run/docker.pid
ps -ef|grep dockerd # 存在 僵尸进程
root 4081 1 0 13:49 ? 00:00:00 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
修复问题方法#
此问题的原因,应该一个是 docker 中存在的一个
bug,解决方法就是:删掉系统其他无关的容器即可,只保留有用容器,此示例中如:rancher_old及创建数据卷备份时使用的容器。
清理容器#
清理僵尸进程#
先执行停止 docker 服务命令, 还是会卡住,不过没关系 使用
ctrl + c,终止即可,目的已达到
service docker stop
yum install psmisc # 安装工具 ,使用 killall
killall dockerd
ps -ef|grep dockerd # 再次检查僵尸进程
进入 docker 对应数据卷的 containers目录下,如未修改路径默认则为: /var/lib/docker/containers#
cd /var/lib/docker/containers\
&& ls

可以看到我这里系统中存在有四个容器,我这里演示的只保留名为
rancher的容器
查找名为 rancher 的容器 id ,并只将其做 保留。
cd /var/lib/docker/containers
for i in `ls */config.v2.json`;do grep -l '"Name":"/rancher"' "$i";done|awk -F '/' '{print $1}'
96d6ea117475ffab7c5651812163ca45feded54463d93e992f9195964ae81282 # 找到 id
rm -rf !(96d6ea117475ffab7c5651812163ca45feded54463d93e992f9195964ae81282) # 谨慎确认后 执行
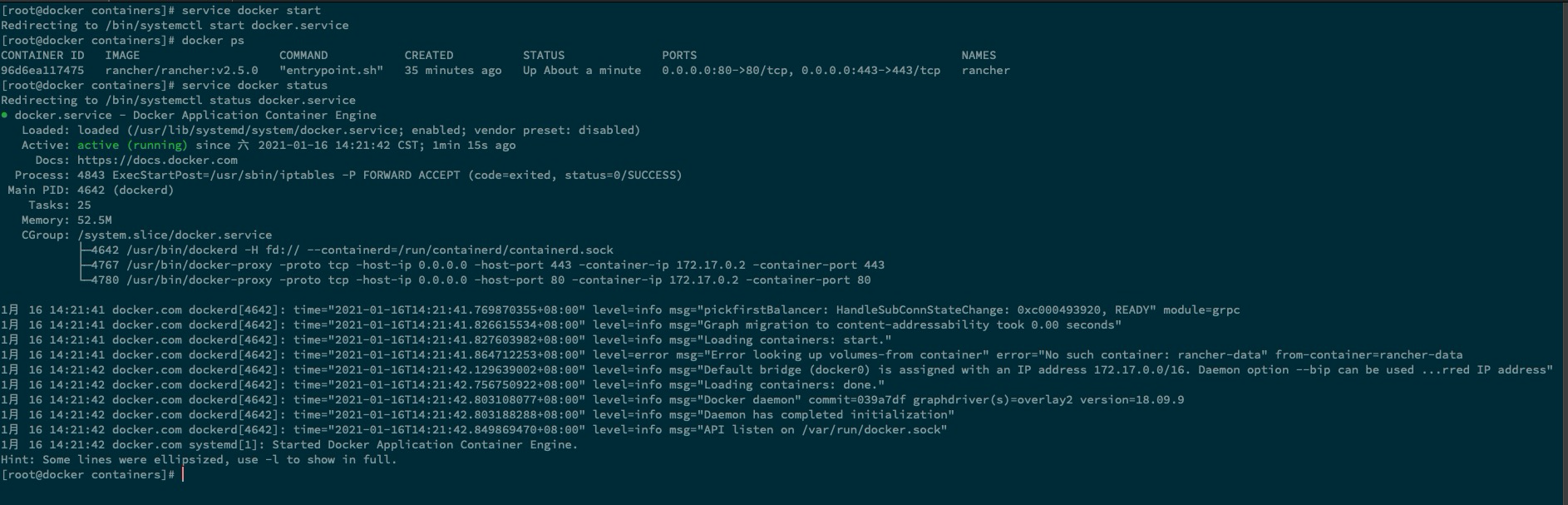
再次启动 docker 时,已可以正常启动
service docker start
总结#
此 docker bug 在 18.x 中 测试存在,如在升级和使用 docker 的版本时应注意留意此问题。升级完容器后,及时清理无用旧容器,并在升级过程中做好相应的 备份,避免导致数据的丢失。
相关文章
Kind 部署本地k8s集群的使用记录
·326 字·1 分钟·
k8s
docker
devops
centos7
kind
Coredns 出现间断性无法正常解析域名问题
·1536 字·4 分钟·
k8s
coredns
dns
记录一次,因误删容器导致的容器恢复过程
·1707 字·4 分钟·
docker
docker
centos
fix
使用 Docker 部署 Nexus3 私服的详细记录总结
·2798 字·6 分钟·
docker
devops
nexus3
install
部署 Nginx-Ingress 并配置暴露 kubernetes dashboard
·661 字·2 分钟·
k8s
ingress
helm
dashboard
kubernetes 集群中 控制平面 组件频繁发生重启的问题排查记录
·688 字·2 分钟·
k8s
coredns
flannel
fix